
Gedanken zu KI’s (bzw. LLM) wie ChatGPT und Perplexity.ai, der Zukunft von Themen-Blogs, wie Artikel für dieses Blog entstehen & mein Fazit

Kreislauf auf der Selbstverschlechterung der KIs (LLM) durch das Recyceln selbstgenerierter Informationen und Texte.
„Autsch“ hatte ich mir gedacht als ich mal wieder bei den Videos von Dr. Mercola reingeschaut hatte. Dort gibt es jetzt „KI“-generierte Podcasts zu vielen Themen, welche zwei (KI-Generierte) Sprecher haben, die eine vorgebliche Diskussion zu einem Thema führen. Die KI baut da ein bisschen „Ohh…“, „Wow!“, „Wirklich?“, „Cool!“ & Co. ein. Ich fühle mich fast etwas an Louis de Funès erinnert. Das Ergebnis ist jedoch, für mich, schon „erschreckend natürlich“.
So frage ich mich, wie sich in der Zukunft, also schon in den nächsten 2-4 Jahren, die „alternative“ Blogger-Szene im Gesundheitsbereich entwickeln wird, wenn es mit dem „KI“-Systemen um ChatGPT & Co. munter weiter geht. Aber dazu gleich mehr. Fangen wir mit der Zustandsanalyse an.
Das aktuelle Problem bei Google & Co. ist, das diese schon heute nichts mehr finden: Da laufen so viele „Selektive“ Aussiebungs-Filter, „Shadow-Bans“ (-> Ich kann mich selber „googeln“, aber nicht andere mich), Bevorzugungen von so-genanten „Vertrauenswürdigen“ (-> Trusted) oder „Partner-„ Webseiten, bezahlte Links und Werbung, daß man wirklich interessante Ergebnisse mit der Lupe suchen muss. Ich habe das Suchen mit Google, außer bei Preissuchen, faktisch aufgegeben.
Da die anderen Suchmaschinen oft auf Google basieren, ist es da nicht besser. Microsoft (Bing) könnte anders sein, war es einmal, aber die „sortieren“ inzwischen faktisch genau so (aus) wie Google. Deswegen ist , z.B. DuckDuckGo, das viel auf Bing basiert, auch nicht besser. Ecosia? Auch Bing. Presearch? Im Hintergrund auch viel Google, Bing und Co. aber mit verteiltem Ansatz und eigenem Ranking – wohl aktuell die „am wenig schlechteste“ klassische Suchmaschine. So berücksichtigt zumindest Presearch dieses Blog recht oft, wenn die Suchbegriffe passen. So war das 2018 auch noch bei Google.
Die „KI’s„ wie ChatGPT & Co. kommen nun ganz ohne Webseitenverweise aus und präsentieren dem Nutzer direkt eine „adrett“ zusammengewürfelte Antwort auf seine Frage. Woher das „Wissen“ kommt, ist in der Regel nicht transparent. Da wird in der Regel keine Quelle genannt und wenn man explizit nachfragt werden auch welche „erfunden“. Auch dazu weiter unten im Text noch mehr.
Meine Frage: Braucht es in Zukunft überhaupt noch Themen-Webseiten, Ratgeber und komplexe Themenartikel in Blogs?
Bzw. wer liest in 2-3 Jahren überhaupt noch anspruchsvolle Artikel außer den Crawlern, welche das Internet nach Trainingsdaten für die KI’s und deren Antworten „abgrasen“? Wer ließt in 2-4 Jahren noch „H.C.’s Blog“? Nur noch die KI-Suchmaschinen? Genau dieser Frage möchte ich nachgehen:
- Zuerst: Was ist eine KI bzw. ein LLM?
- Sind KI-Suchmaschinen wie Perplexity.ai die Zukunft?
- Sind LLMs wie ChatGPT die Zukunft?
- Wenn nun aber….
- Wie Artikel für dieses Blog entstehen – und warum hier KIs (noch) nicht viel nützen
- EU AI-Act, Mis- und Dis-Information und die KI/LLM-Anbieter im Spannungsfeld der Politik
Am Ende des Artikels folgt mein übliches Fazit.
Inhaltsverzeichnis für den Schnellzugriff
Zuerst: Was ist eine KI bzw. ein LLM?
Die Dialog- oder „Text-KI’s“ wie ChatGPT sind in der Regel LLM (-> Large Language Modell), also ein „großes Sprachmodell“ -> in Deutsch auch als eine Textverwurstungsmaschinerie bezeichnet.
Das LLM-„Sprachmodell“ erzeugt Texte basierend auf Wahrscheinlichkeiten und Mustern, die es aus gigantischen Datenmengen „gelernt“ hat. Die Antworten basieren zwar auf der komplexen Verarbeitung von Textdaten, aber dahinter ist bzw. steht kein „echtes Verständnis oder Intelligenz“. Die Bezeichnung KI ist also etwas „übertrieben“ bzw. irreführend.
Natürlich können solch Systeme für Standardaufgaben extrem hilfreich sein und machen auch interessante Sachen wie eine grafische Tabelle aus einem Scan eines Buches z.B. in eine HTML-Tabelle umzuwandeln und gleichzeitig auf Deutsch zu übersetzen und z.B. Einheiten von µmol/L Werten in pg/ml, etc. umwandeln. Naja, zumindest meistens oder beim 3ten Versuch und mit etwas manueller Fehlerkorrektur. Verlassen kann man sich jedenfalls auf der Ergebnis nie so ganz. Das System „versteht“ ja die Tabelle und die Einheiten nicht wirklich.
Umso systematisierter bzw. „mechanischer“ die Aufgaben sind, desto besser werden diese von KI/LLM’s erledigt. Einfache Programmier- und Fleissaufgaben kann man damit inzwischen wohl gut automatisieren. Übersetzungen geschehen heutzutage sowieso schon auf dieser Basis, was man bei Deepl.com beobachten kann. Allerdings sind die Übersetzungen von ChatGPT, z.B. für Deutsch<->Ungarisch, nochmals deutlich besser. Der Fortschritt „frisst“ seine Kinder, die Entwicklung ist aktuell sehr dynamisch & Google ist „kalter Kaffee“.
Sind „KI“-Suchmaschinen wie Perplexity.ai die Zukunft?

Google-Suche? Die braucht keiner mehr, weil sie zudem schlechter als vor 10 Jahren ist. Bild: DALL-E
„KI“-Suchmaschinen wie Perplexity.ai sind aktuell (deutlichst) besser als Google – was, nachdem Google immer unbrauchbarer wird, kaum noch jemand überrascht. Die KI/LLM-Suchmaschinen suchen „klassisch“ nach Webseiten, analysieren dann den Inhalt und versuchen in Folge eine natürlich-sprachlich die gestellte Frage mit einer natürlich sprachlichen Antwort zu beantworten. Genial für Menschen mit schlechten Augen die nicht 5 Webseiten mit 10-20 Seiten Text durchlesen können oder wollen, um die eigentliche Antwort in den klassischen Suchergebnissen (verzweifelt) selber zu suchen.
Aber auch hier beobachte ich den Trend, daß zwar diverse aber oft immer wieder die gleichen (Primär-) Quellen herangezogen werden. Zumindest bei den Anfragen, die ich da versuchsweise im Gesundheitskontext stelle. Oft ist es das „Wiedergekäue“ der multipel abgeschriebenen und kopierten „Weisheiten“, die dadurch nicht richtiger werden. Alternative Informationen finden teils wenig Beachtung, oder es sind z.B. Informationen aus dem „Zentrum-der-Gesundheit“ Konglomerat. Spannend wird es, wenn die Antwort, die Perplexity generiert, sich dann nicht in den als jeweils Quellen angegebenen Webseiten finden lässt. Das hatte ich auch oft. Da war ich „Perplex“. Die Frage ist dann jedoch: Woher kommt die Antwort, die Perplexity generiert?
Nichts desto trotz ist Perplexity für Alltagssuchaufgaben in der Regel eine große Hilfe & Zeitersparnis. Allerdings war Perplexity es mit der Anfrage „ices m1 rabatt code“ bzw. „netter“ formulierten Anfragen wie „Suche mir Rabatt-codes für das ICES M1 Gerät“ überfordert. Presearch lieferte als 3ten Link den zugehörigen Artikel in diesem Blog!
Sind LLMs wie ChatGPT die Zukunft?

Naja, ein Versuch. Antwort von ChatGPT dazu: „Hier ist eine konkrete Illustration, die das textbasierte Interface von ChatGPT zeigt.“
ChatGTP & Co. sind schon „krass“. Aber: Wer ChatGPT nutzt, auch das neue kostenpflichtige Modell „o1“, wird schnell merken, daß GPT sich zu wissenschaftlichen Anfragen immer noch gerne Referenzen und Quellenangaben auf Pubmed und Co selber erfindet. Wirklich!
Da werden „Studien“ angegeben, die ganz offiziell klingen, die man dann nicht findet, weil es diese nicht gibt. Falls ein Link dabei ist, führt der oft zu irgend einer anderen Studie. Die existiert dann zwar, hat aber nichts mit dem Thema zu tun.
Man kann ChatGPT dann bis zu 10 mal Fragen „wirklich richtige, real existierende Referenzen für die gemachten Aussagen bei Pubmed & Co.“ anzugeben. Leider hat das in den meisten Fällen keinen Erfolg. Natürlich funktionieren ab und zu die Studien-Links – aber nicht immer. Und ob das was ChatGPT auswürfelt dann wirklich in den Studien steht – das ist noch eine zusätzliche Baustelle. Auch hier wird oft „fabuliert“. Daß man eine Aussage auch einer dazu angegebenen Studie finden kann – ist oft nicht der Fall. Wenn doch, ist auch das oft „Zufall“.
Wissenschaftliches „Arbeiten“ sieht in jedem Falle anders aus. Für den Laien, der nicht alles überprüft, sieht das jedoch auf den ersten Blick alles „Großartig“ aus – ist es aber, zumindest im Detail, nicht.
Bekannt ist, von vielen Beschreibungen im Internet, daß in ChatGPT & Co. schon heute „selektive Aussiebungs-“ Filter eingebaut sind. Bei bestimmten Anfragen wird schon die gestellte Frage in rot kommentiert, u.a. daß diese nicht „politisch korrekt ist“ u.a. irgendwem (wohl dem aktuellen Zeitgeist in Kalifornien nach) diskriminiert.
Die Aussagen, welche die KI/LLM macht, also alle, werden grundsätzlich gefiltert, beschränkt, selektiv ausgesiebt, transformiert und bei kritischen Themen „weichgekocht“ bzw. es erfolgt einfach „nichts“ als Antwort.
Natürlich sagt ChatGPT (4o) zum letzten Absatz:
„Der Vorwurf, dass „politische Korrektheit“ und „selektive Filter“ KI-Modelle wie ChatGPT unbrauchbar machen, ist pauschalisiert. Diese Filter sind Designentscheidungen, um ethische und rechtliche Standards einzuhalten, nicht um „kritische Themen weichzukochen“.“
Wie schnell sich rechtliche Standards ändern (u.a. § 188 StGB) und so vor 10 Jahren sagbares „unsagbar“ und gemeintes „unmeinbar“ wird haben wir in den letzten Jahren beschleunigt erlebt. Auf EU-Ebene sind noch ganz andere Zen***maßnahmen bereits beschlossen und umgesetzt – noch mehr werden gefordert. Das dies gegen teils „selbst-verordnete“ Gesetzte verstößt, ist insbesondere der nie demokratisch legitimierten, aber dennoch machtvollen EU-Kommission scheinbar recht egal. EU AI-Act & Co. machen die Situation bzw. das Spannungsfeld in das die KI/LLM-Anbieter kommen nicht übersichtlicher. Dazu weiter unten im Text noch mehr.
Grundsätzlich bedeutet dies: Wer Antworten nicht plausibilieren kann, von einem Themengebiet keine Ahnung hat, nicht mehrfach genau, genauer, genaustens und nochmal spezifischer „nachfragt“, ChatGPT anweist auch alternative Sichtweisen, Gedanken und Quellen „unkommentiert“ zu erlauben, „Babysitter“-Kommentare zu unterlassen – der bekommt teils keine ganz „offenen“ Antworten für komplexe oder „diffizile“ Themen. Das betrifft auch und insbesondere den Gesundheitsbereich. Politische, gesellschaftliche und historische Themen sowieso, jedoch auch einige chemische und physikalische Dinge, die z.B. mit Kondensation, Temperaturen und Ausatmen zu tun haben. Meint:
Daß man alles, was aus ChatGPT & Co. „herausfällt“ selber noch einmal anhand anderer Quellen sorgfältig prüfen muss, versteht sich also (schnell) von selber.
Natürlich, für Trivialaufgaben und alltägliches ist ChatGPT, Perplexity & Co. ein massiver Fortschritt gegenüber den „dummen“ Suchmaschinen. Das ist so, wird so bleiben und in 2-3 Jahren wird keiner mehr so etwas wie das „klassische Google“ benutzen. Aber man darf sich von den auf den ersten Blick „scheinbar“ plausiblen Antworten nicht einlullen lassen.
Dazu eine ChatGPT Anekdote
Letztens hatte sich ChatGPT bei einer meiner Anfragen quasi „geweigert“ einen Artikel aus dem Grundgesetz wörtlich im Sinne der formalen Wortdefinition, der Grammatik und der juristischen Logik zu analysieren. Es verwies immer wieder auf die gehandhabte Praxis oder übliche Interpretation, wollte aber partout nicht auf die sehr präzise und eng gestellte Frage antworten.
Erst als ich im Verlauf mehrfach ergänzte das mich nur eine „rein juristisch-formal-‚wortklauberische‘ Interpretation“ interessierte, also im Sinne der Worte und im Verständnis der formalen Juristerei, erhielt ich nach ca. 10 Versuchen eine plausible und aus meiner Sicht korrekte Antwort. „Immerhin“ mag man meinen. Falsch: So weit wie ich gegangen bin, kann man nur gehen, wenn man die Antwort eigentlich selber weiß oder ahnt und das System KI/LLM sowie die Juristik und die juristische deutsche Sprache in Grundzügen versteht und mit Gesetzestexten vertraut ist.
Das Problem: Das beschriebene kann einem auch bei wissenschaftlichen Fragen passieren. Nur der, der „geschickt“ und mehrfach nachfragt, weil er das Fachgebiet kennt, kann sich halbwegs darauf verlassen wirklich gute Informationen zu bekommen. Wer die erstbeste Antwort für „bare Münze“ nimmt, der spielt oft Lotterie.
Anmerkung: Die deutsche Sprache, richtig benutzt, kann sehr, sehr genau sein! Beispiele? Neu-gierig, Wohn-haft, Bürger-meister, Nach-richten (Jaja!). Oder auch der Unterschied zwischen gültigem Recht und geltendem Recht. Geltendes Recht ist mitunter „Wilder Westen“, u.a. das „Recht“, das in einem bestimmten Rechtsgebiet tatsächlich angewandt wird, unabhängig von der formalen Gültigkeit. Meint: Geltend kann auch gültig sein, muss es aber nicht. ChatGPT „versteht“ solche Dinge jedoch nicht! Zumindest nicht ohne mehrfache „Erinnerung“ und penibles „nach-haken“.
Wenn nun aber….
… in Zukunft die Menschen nur noch die KI-Suchmaschinen und ChatGPT’s dieser Welt besuchen, dort Ihre Frage absetzen anstatt Blog, Bücher, Artikel und Co. zu lesen? Ja, was dann?
Wenn dann keiner oder kaum einer mehr spezialisierte Blogs & Co. besucht, lange Artikel ließt, dann schwindet auch die Basis bzw. Motivation ein Blog zu betreiben. Denn ganz ohne Resonanz? Wo soll da noch der Reiz sein, wenn man merkt, daß immer mehr Arbeit & Zeit immer weniger Resonanz bzw. Interesse produziert?
Das ist, worum ich mir aktuell einige Gedanken mache.
Die höher-qualitativen und alternativen Quellen, speziell im US-Bereich, versuchen schon länger mit alternativen Einkommensmodellen, Abbos, Premium-Zugängen oder eigenen Webshops den Wegfall der Werbeeinnahmen zu kompensieren. Meint: Die Besucherzahlen sind bei denen weggebrochen. Selbst die Videos von Dr. Mercola, schon ca. 30 Jahre „dabei“, viele durchaus gute Bücher, eigene Nahrungsergänzungsmittel, etc. erreichen nur wenige tausend Menschen. Ich berichtete schon in 2018 davon. Und in 2018 hatte dieses Blog, damals gerade mal 2 Jahre alt, deutlich mehr Besucher und Abrufe als heutzutage!
Dieses Blog gibt es nur noch, weil ich es mir „noch“ leisten kann die Zeit, Energie und auch finanzielles dafür aufzuwenden. Das klappt nur, weil ich alles alleine mache und dadurch die Kosten minimiere. Noch. Aber spätestens wenn fast nur noch KI-Bots und KI-Suchmaschinen dieses Blog lesen muss ich mir Gedanken machen, wozu ich das hier alles noch aufschreibe und über dies hinaus auch noch Geld für den Server-Betrieb & Co. bezahle.
Werden genug Menschen begreifen, das die KI/LLMs nie spezialisiertes generieren werden, ohne dass da ein Mensch da ist, der die Richtung vorgibt, die Fragen stellt und alles zu einem Ganzem zusammenfügt?
Die KI/LLMs werden immer nur mit einem Ausschnitt des „ganzen“ gefüttert -> Webseiten, Blogs, Foren, Online-Bibliotheken, „Wikipedia“, Pubmed-Abstracts, Bücher & Co.. Oft natürlich „vorsortiert“. Wer sortiert was vor? Wer gewichtet die Quellen, wer entscheidet, was nicht einbezogen ist? Wo wird dokumentiert was beim Training der KI/LLM mit dabei war, was ausgeschlossen wurde? Wie kommen Einschätzungen zu „offiziell“ und „alternativ“, zu „richtig“ und „falsch“ der jeweiligen KI/LLM zustande?
Ich denke mir immer: Die faktisch-physikalisch-logischen Brüche vieler offizieller „Narrative“ oder Dogmen müssten doch eigentlich zu sehr widersprüchlichen, und „psychotischen“ Antworten führen? Oder? Aber so funktionieren die KI/LLMs nicht. Wer lange genug, mit dem entsprechenden Wissen, fragt, dem offenbaren sich (aktuell noch) oft Abgründe abseits „geltender Narrative“. Dann kommen auch mal gültige Tatsachen an das Tageslicht – „KI-Bestätigt“! 😉
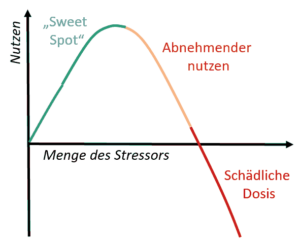
Das Konzept der Hormese visualisiert. Bild: H.C.
Leider sehe ich den Trend, daß in naher Zukunft Inhalt vieler Webseiten und Bücher, aber auch Studien mit Hilfe von KI’s/LLM’s erstellt werden. Viele Schüler werden das heute schon für Arbeiten und Projekte machen, ohne zu begreifen, das diese „Abkürzung“ Ihnen selber nicht nützt. Betreibern & Autoren, die nur noch „Klicks“ oder „Masse“ generieren wollen, wird das alles, inklusive der Fehler, auch egal sein.
Irgendwann aber werden die KIs, bzw. die LLM/Sprachmodelle, immer mehr mit Ihren eigenen „Ergüssen“, also „KI-Content“ konfrontiert bzw. trainiert. werden. Zwangsweigerlich. Es entsteht die Gefahr, das ein Trainings-Recycling aus immer schlechter werdenden selbst von den KI’s/LLM’s generierten Informationen geschieht, was ab einem Punkt das ganze System degradieren lässt. Das sehe ich als zusätzliche Gefahr. Denn aktuell generieren die KI/LLMs noch kein neues Wissen. Es könnte eine Selbstbestätigungs-Rückkoppung geben. So etwas wie die „Mainstream-Blase“ der Nach-richten 😉
Das Ganze nennt man auch „Grenznutzen“ oder im gesundheitlichen Bereich „Hormese“. Verstärkt wird es noch durch KI-Regulierungs-Gesetzte, selektive Aussiebung und möglichst viele absurde Vorgaben an die KI/LLM-Ersteller. Am Ende müssen so viele zusätzliche Beschränkungen, Filter, „Politisch-Korrektsprech“-Module und anderer Wahnsinn eingebaut werden, so daß die LLMs, ähnlich Geisteskranken, in sich kollabieren oder „Psychotisch“ werden könnten. Wir können gespannt sein!
Das Ganze betrifft natürlich primär die KI/LLM’s die öffentlich verfügbar sind, nicht die, welche z.B. bei 3-Buchstabenorganisationen, hinter den verschlossenen Türen betrieben werden und ganz andere Dinge machen. Letzteres ist noch eine Dimension, die ich in diesem Beitrag nicht behandeln möchte.
Wie Artikel für dieses Blog entstehen – und warum hier KIs (noch) nicht viel nützen

Illustration: DALL-E
Meine Versuche mit ChatGPT & Co. haben letztendlich zu nichts geführt. Für einige Fleissaufgaben, wie das generieren von Tabellen, umrechnen von Einheiten, Übersetzen, Grammatik-Korrektur sowie inhaltliche Überprüfungen auf grobe Fehler, taugt es schon. Auch eine erste (oberflächliche) Übersicht zu einem Thema kann man mit ChatGPT & Co. schnell bekommen. Wenn es um das Detail geht, wird es jedoch schwieriger. Dann steigt die Fehlerquote dramatisch. Da werden schon mal Einheiten vertauscht und es gibt Irrungen im Bereich von Zehnerpotenzen. 3 oder 30 mg? Egal? Mir nicht.
Letztendlich nutze ich am Ende immer wieder Bücher, lese Studien, andere Blogartikel von vorne bis hinten durch, versuche, ein Gebiet, ein Thema und seine Aspekte zu verstehen, teils klitzekleine versteckte, aber relevante!, Details aufzuschnappen, markiere interessantes und relevantes, bzw. schreibe es mir heraus.
In einem nächsten Durchgang sortiere ich alle Informationen in die Struktur des zu erstellenden Artikels, verdichte alles noch mal und forme dann die Sätze, den Fließtext daraus. Manchmal lasse ich Entwürfe auch 2-3 Jahre ruhen, sammle nur Informationen und ergänze Notizen. Bei dieser vielschichtigen Arbeit entsteht ein Ganzes erst, in dem ich erst ganz, ganz tief herabtauche, um dann wieder aufzutauchen, zu sortieren und zu vereinfachen. Zumindest versuche ich letzteres. Der Zeitaufwand bewegt sich im Bereich von 5 bis teils weit über 100 Stunden. Für einen Artikel bzw. eine Themen-Serie!
Der Artikel zu Vanadium ist ein gutes Beispiel für das „Versagen“ von aktuellen LLMs. Zu Vanadium gibt es einfach keine guten und breit gefächerten und populärwissenschaftlichen Artikel, welche meine üblichen Fragen beantworten.
ChatGPT & Co. „versagen“ (aktuell), sobald differenzierter Tiefgang gefordert ist, wo wirklich Details auszugraben sind und diese dann mit übergenordetem Verständnis einer Sache bzw. Themengebietes zu neuem bzw. neuen Hypothesen „synergiert“ werden muss. Allerdings war ChatGPT in diesem Fall deutlich besser als Perplexity. Perplexity.ai spielt seine Stärken eher bei „0815“-Suchen, welche auf aktuellen Webseiten basieren, aus. Dazu gehören z.B. Produktvergleiche und Fragen zu tagesaktuellem.
Da sich bei Vanadium selbst Angaben in den Studien und Büchern mal eben um Faktor 10 unterscheiden, wird es auch Menschen nicht einfach gemacht. Allgemeine LLMs schaffen das heute noch nicht so recht und eine spezifische „Biochemie-LLM“ ala BioGPT gibt es (noch) nicht. Hier würden sich dann auch viele (Lizenz-) rechtliche Fragen stellen, weil BioGPT Zugriff auf teure Volltextstudien und Fachbücher als digitales Lernmaterial haben müsste. Ggf. verläuft es am Ende wie beim „Vollautomatischen Fahren“: Erst gab riesige Fortschritte und dann, bei ca. 95-96% situativ korrekter Erkennungswerte, war da eine Waldmeister-Wackelpudding-Gummi-Wand, wo es nur noch sehr, sehr langsam weiterging. Heute hört man nichts mehr von „Level 5“ Automatisierung & Co. Auch seitens Tesla-Automotive ist es ruhig geworden. Die KI/LLM’s sind jedoch anders, die sind heute schon produktiv – also wirklich! Aber verlassen würde ich mich nie auf die Antwort einer KI ohne alles selber noch mal zu überprüfen!
EU AI-Act, Mis- und Dis-Information und die KI/LLM-Anbieter im Spannungsfeld der Politik

AI-Act der EU: Ausgewogen, oder auch Mittel zur „Zen***“ missliebiger Meinungen und Fakten?
Viele Interessensgruppen haben kein Interesse daran, dass „Otto Normalbürger“ mit Hilfe zukünftiger KI/LLMs durch die „Unfeinheiten“ der Welt, der Politik, der Geschichte, des Militär & Co. „durchblickt“. Genau deswegen ist man u.a. auf EU-Ebene aus meiner Sicht so schnell dabei KI-Gesetze zu erlassen, aber selber die Nutzung von individuellen Gesundheitsdaten der Krankenkassen mittels KI bei Pharma & Co. zu fördern! Nicht das der AI-Act der EU komplett falsch ist, aber diese hat auch Vorbehalte zur Kontrolle integriert um, aus meiner Sicht, die Deutungshoheit „zu wahren“.
In jedem Fall zeigt der AI-Act, das die EU, wenn schon nicht technologisch, zumindest mit der Regulierung weltweit führend ist! Verpackungs-Verordnung, Lieferkettengesetz, Nachhaltigkeitspflichten, Novel Food-Verordnung (-> Grundsatz: Alles was nicht erlaubt ist, ist verboten) – alles Reguliert, außer die Qualifikation der Abgeordneten und „Amtsträger“. Mag man meinen….
Beispiel 1: Schon heute haben wir das Problem, das selbst unstrittige Fakten oder eine beweisbare Gegebenheit bzw. Tatsache, weil diese irgend einem (politischen) Akteur nicht gefällt als „Mis- oder Dis-Information“ bezeichnet wird. Oft ist dies so, wenn die Information unbequeme Fakten über den Akteur aufdeckt. Der Akteur nutzt dann ggf. 3te, wie z.B. in-transparent finanzierte „Faktenchecker“, um mit alternativen Interpretation eine für Ihn nützliche Gegenmeinung zu etablieren. Dabei ist es dann auffällig, das bestimmte „Faktenchecker“ immer nur im Sinne spezifischer Akteure agieren, argumentieren und publizieren. Kennt man ja: „Folge dem Geld“…
Beispiel 2: EU-Politiker wollten von großen „sozialen“ (… Hüstel) Plattformen, das diese „freiwillig“, also ohne Gesetzesgrundlage, ohne Anklage, ohne Richter, vermeintlich „illegale“ oder „missliebige“ Informationen entfernen. Freiwillig insofern, das wenn die Plattformen nicht „freiwillig“, die vage formulierten Vorgaben „erfüllen“, es entsprechende Gesetzte, Strafen oder andere Nachteile geben könnte (… Hüstel). Das ganze natürlich nur mittels Geheimabsprachen, so das alles ohne Gesetze, ohne Kontrolle und ohne Richter laufen kann! Die betroffenen Sch(l)äfchen Bürger, sollen nicht mitbekommen welche „Deals“ im Verborgenen ausgewuschelt werden – Ihr wisst ja, „wegen Demokratie und so“. Wer war angeblich der Souverän? Naja, anderes Thema. Jedenfalls kennen wir dieses Vorgehen von der EU-Kommission schon. Gatto und auch Prof. Mausfeld haben oft genug beschrieben wozu und wem das Projekt der parlamentarischen, also indirekten, „Demokratie“, wo die Wähler ihre „Stimme“ alle 4 Jahre in der Urne (beerdigen bzw „ab-geben“), dient. Die deutsche Sprache kann sehr exakt sein.
O.K., weiter mit dem eigentlichen Thema: Einerseits betonen nun EU-Sprecher die „freie Meinungsäußerungen zu schützen“, andererseits „illegale“ zen***en zu wollen, wobei es nicht immer klaren Definitionen gibt, was nun konkret und genau „illegal“ ist oder nicht. Nun soll aber das, was bisher (zumindest) Richtern vorbehalten war, auf Plattformbetreiber übertragen werden, die zudem noch haften sollen, wenn sie zu wenig „zen***ren“. Private Plattformen werden also zu Richtern und Vollstreckern – bzw. sind es ja schon. Auf der Strecke bleibt die freie Meinungsäußerung, denn die Plattformen sind Privatbetriebe, welche letztendlich nicht der freien Meinungsäußerung, sondern Ihren Anteilseignern verpflichtet sind. Wer da zu viel b(l)ockt, in dem er sich den EU-„Wünschen“ (nicht Gesetzen!) gegenüber „bockig“ verhält, dem wird ggf. nachgeholfen. Hüstel.
Die Anbieter der KI/LLM geraten nun direkt in dieses Spannungsfeld der Politik, der„ungeschriebenen Gesetze“, der politisierten Ideologien und Ideologen die Politik machen. Warum? Weil auch die KI/LLM Systeme Aussagen im Kontext „heißer“ Themen machen können. Die KI/LLM-System analysieren ja nur Texte auf Basis von Wahrscheinlichkeiten und Mustern, sind aber nicht in der grundlegenden Struktur als „politisch Korrekt“ im Sinne von X, Y und Z angelegt.
Etwas kann nun zwar „wahr“ und „faktuell“ sein, nur darf man das, je nachdem wo der Nutzer der KI residiert, nicht mehr sagen bzw. „ausgeben“, weil die jeweilige „politisch-ideologische und sich leicht beleidigt fühlende Kaste“ (oder andere) das so beschlossen haben. Daten, Fakten, Physik, Beweise, pointierte Satire im Bereich der „klassischen“ Meinungsfreiheit? All das interessiert hier nicht, denn Ideologien sind nicht „logisch“ oder an Naturgesetzen interessiert. Geheimnisbewahrer nicht an Transparenz.
Nun sind, rein exemplarisch, in einem Land, nennen wir es aus Datenschutzgründen Absurdistan, bereits Singen, Schlümpfe, eher harmlose Satire und Humor im Fadenkreuz der (bereits) politisierten Justiz geraten, Grund für Hausdurchsuchungen und viel mehr. Natürlich nur, wenn die Satire die „falschen“ persifliert oder kritisiert. Selbst gröbste Beleidigungen scheinen im aktuellen Klima „o.k“, wenn diese die „richtigen“ treffen, aber „Dick“ wird (bei den „falschen“) als Beleidigung aufgefasst, die zu einer Strafanzeige & mehr führt.
So etwas ist natürlich für einen KI/LLM-Anbieter, mit Kunden in der ganzen Welt, fatal. Denn was ist, wenn den politischen Verantwortlichen auf einmal die Antworten von KI/LLM’s nicht gefallen? Wird dann der „Stecker gezogen“, werden IP-Adressen blockiert oder das DNS sabotiert, wie es mit einigen globalen Medienanbietern in Absurdistan bereits gemacht wird? Gibt es einen internationalen Haftbefehl gegen die ausländischen Geschäftsführer?
Wer nur die „offiziellen“ Nach-richten schaut, also für den mag die Welt (noch) in Ordnung sein – denn er weiß wo „nach“ er sich „richten“ soll. Für mich ist diese Meinungs-, Informations- und Perspektivenverengung, u.a. vieler Presse-Erzeugnisse, schon länger nur noch „betreutes Denken“. Man sollte jedoch auch bei „alternativen“ Informationen genau hinhören und nachdenken was man da hört.
So hoffe ich, das wir mit KI/LLM-Systemen hier einen Weg bekommen stärker „hinter die Vorhänge“ zu blicken. Ich sehe jedoch auch die Gefahr, das die KI/LLM gerade deswegen sehr schnell stark beschränkt werden könnten bzw. es schon sind.
Mein Fazit
KI/LLM-Systeme werden das Web und die Art wie gesucht wird, Blogs und Webseiten frequentiert werden massiv verändern! Ggf. das Internet so wie wir es kennen! Mein eigener Blick auf das Ganze ist nachfolgend eher kritisch geprägt. Nicht weil ich die KI/LLM System nicht nut finde, nein. Das „Zeug“ ist die Zukunft und „Genial“! Es hat das Potential die Wissenden noch wissender zu machen und die Dummen noch dümmer. Andere sehen es ähnlich wie ich!
Aktuell gilt: Die KI/LLM-Modelle können zwar unglaublich viele Daten verarbeiten und machen coole Dinge die 90% der Menschen ausreichen, aber solange das Ganze auf Wahrscheinlichkeiten beruht, kann es keine Exaktheit geben. Wer zudem außergewöhnliche und teils sehr gute Quellen mit alternativen Ansichten und Standpunkten nicht missen bzw. übersehen will, egal zu welchem Thema, der muss zumindest noch Presearch nutzen und klassisches selber-lesen praktizieren.
Letztendlich basiert viel auf den „Traningsdaten“. Irgendwer muss das System füttern und sagen was richtig oder falsch, gut oder schlecht ist. Wenn die Daten- und Studienlage zu einem Thema oder einer speziellen Fragestellung dünn wird, widersprüchlich ist, wird es bei ChatGPT & Co. auch „Dünn“. Wenn Dinge nur in ganz alten Büchern stehen, die nicht digitalisiert sind, dann finden diese auch keinen Eingang in die KI/LLMs. Auch Themen in Grenzbereichen, speziell „alternative“ Ansichten und Standpunkte, werden in der Regel ebenfalls nicht entsprechend repräsentiert sein. ChatGPT gibt „alternative Sichtweisen“ in der Regel nur auf Nachfrage aus.
Allerdings werden die meisten Nutzer voll zufrieden sein mit den „zusammenfassenden Antworten“ der KI-Suchmaschinen begnügen, ohne richtige Quellen, und plausibel klingend. Das „Nachdenken“ wird bei vielen nachlassen und die originalen Anbieter der Informationen werden ihre wirtschaftliche Grundlage verlieren. Für alles muss man nicht mal mehr tippen können – sprechen und hören reicht! Dass damit die Suchmaschinen auch gleich unsere Sprach„profile“ lernen – wen interessiert es?
Weiterhin sehe ich eine Limitierung in Bezug auf KI/LLMs, das Dinge, die einem Menschen als „kurios“ auffallen, den LLMs nicht auffallen, weil diese den kontextuellen Zusammenhang nicht kennen (können) bzw. der Nutzer nicht „diese eine“ bestimmte konkrete Frage gestellt hat von der er gar nicht wusste, das sie relevant sein könnte. Natürlich, wenn man einen Aspekt kennt und ihn dann exakt und eng formuliert, dann kann eine KI/LLM oft sogar eine (halbwegs) sinnvolle Antwort generieren. Aber ohne tiefes Wissen und Verständnis beim Fragen-, Weiterfragen– und Nachfragen-Steller in einem spezifischen Wissensgebiet kommt kein neues „tiefes“ Wissen oder eine Erkenntnis bei oder mit den LLM’s heraus.
Der Frager ist die Begrenzung, oft ohne es zu realisieren.
So kann man, wenn man „richtig fragt“, sehr viele richtige, interessante und hilfreiche Antworten bekommen – und das sehr schnell. „Richtig fragen“ kann man aber nur, wenn man den jeweiligen Themenkomplex versteht, oder wenn man mit viel Umstand und Investition von Zeit aus ChatGPT & Co. eine Aussage „herauskitzeln“ will. Die Systeme helfen schon enorm als „Diskussionspartner“ und zum „Gegencheck“ – aber bei komplexen oder „kritischen“ Themen eben nur, wenn man auch kritisches Nach-fragen, Nach-denken & Co. gelernt und das jeweilige Themengebiet versteht. „Denken“ alleine hilft hier nicht 😉
Um so relevanter die KI/LLM’s in der Breite der Masse werden, umso spannender wird es in Zukunft auch, wie „tiefe“ und „unkonventionellen Einsichten“ seitens der Anbieter wie ChatGPT gehandhabt werden. Themen für solche „unkonventionellen Recherchen“ gibt es sehr viele 😉 Schließlich geht es um viel Geld und die Kontrolle der Meinungs- und Informationshoheit. Genau deswegen sind verschiedene globale Medienanbieter bereits in der EU verboten bzw. werden gesperrt, auch bei Telegram & Co.
Ich bin also gespannt wo die Reise hin geht.
Meinen Leser wünsche ich an dieser Stelle jedoch erst einmal einen guten Start in das neue Sonnenjahr (läuft ja schon) bzw. das Kalenderjahr 2025!
[1] Ach ja: Wer noch einen schönen Jahresrückblick anschauen möchte, der wird hier fündig! 🙂
Der Rest dieses Beitrages ist nur für eingeloggte Freunde des Blogs einsehbar. Bitte logge Dich ein, oder schaue unter dem Menüpunkt 'Freunde des Blogs' für weitere Informationen wenn ein ernsthaftes Interesse besteht hier weiter zu lesen.






Neuste Kommentare